Article Text

Abstract
Artificial intelligence (AI) broadly refers to analytical algorithms that iteratively learn from data, allowing computers to find hidden insights without being explicitly programmed where to look. These include a family of operations encompassing several terms like machine learning, cognitive learning, deep learning and reinforcement learning-based methods that can be used to integrate and interpret complex biomedical and healthcare data in scenarios where traditional statistical methods may not be able to perform. In this review article, we discuss the basics of machine learning algorithms and what potential data sources exist; evaluate the need for machine learning; and examine the potential limitations and challenges of implementing machine in the context of cardiovascular medicine. The most promising avenues for AI in medicine are the development of automated risk prediction algorithms which can be used to guide clinical care; use of unsupervised learning techniques to more precisely phenotype complex disease; and the implementation of reinforcement learning algorithms to intelligently augment healthcare providers. The utility of a machine learning-based predictive model will depend on factors including data heterogeneity, data depth, data breadth, nature of modelling task, choice of machine learning and feature selection algorithms, and orthogonal evidence. A critical understanding of the strength and limitations of various methods and tasks amenable to machine learning is vital. By leveraging the growing corpus of big data in medicine, we detail pathways by which machine learning may facilitate optimal development of patient-specific models for improving diagnoses, intervention and outcome in cardiovascular medicine.
- heart disease
Statistics from Altmetric.com
Introduction
Artificial intelligence (AI) and machine learning are umbrella terms for a set of algorithms, which allow computers to uncover patterns and make decisions from data. After emerging from a quiescent period, the capabilities and potential of AI in a variety of tasks from automated ‘digital assistants’ to self-driving cars are a ubiquitous component of popular culture. However, despite several promising developments and some progress in oncology, cardiovascular medicine has not yet experienced a similar AI revolution. Routine care of cardiovascular patients accumulates large amounts of data in electronic health records (EHR). The integration of significant amount of diverse data is challenging in a busy clinical setting, resulting in marked underutilisation of information that could influence clinical decisions. Furthermore, much of the research that drives biomedical care comes from conventional hypothesis-driven research studies that often explore a handful of preselected variables and their impact on cardiovascular phenotypes. In contrast, AI-based methods can use a multitude of variables in a hypothesis-free approach to enable data-driven discovery which can identify similarities and differences in patient phenotypes, standardise clinical diagnosis, improve existing therapies, find new drug targets, optimise care pathway modelling and help us deliver data-driven, high-quality precision care at an increased rate.1 2
AI-based methods are increasingly being applied to cardiology to interpret complex data ranging from advanced imaging technologies, EHR, biobanks, clinical trials, wearables, clinical sensors, genomics and other molecular profiling techniques. Advances in high-performance computing and the increasing accessibility of machine learning algorithms capable of performing complex tasks (eg, deep learning and reinforcement learning) have heightened clinical interest in applying these techniques in research and clinical care. In this article, we summarise the current opportunities and pitfalls of the application of machine learning in cardiovascular medicine. There is a growing need for robust, scalable workflows and connecting patient communities, providers, payers and healthcare technology industry stakeholders for the seamless adoption of machine learning approaches. There is also an imminent need to develop guidelines for data acquisition, data sharing, security and privacy protection, and standardisation of machine learning towards implementation of precision medicine. There remain significant challenges in the application of machine learning to cardiovascular medicine, and improved care will only result from enhanced dialogue and teamwork between clinicians, biomedical informatics scientists and machine learning experts.
Big data in cardiology
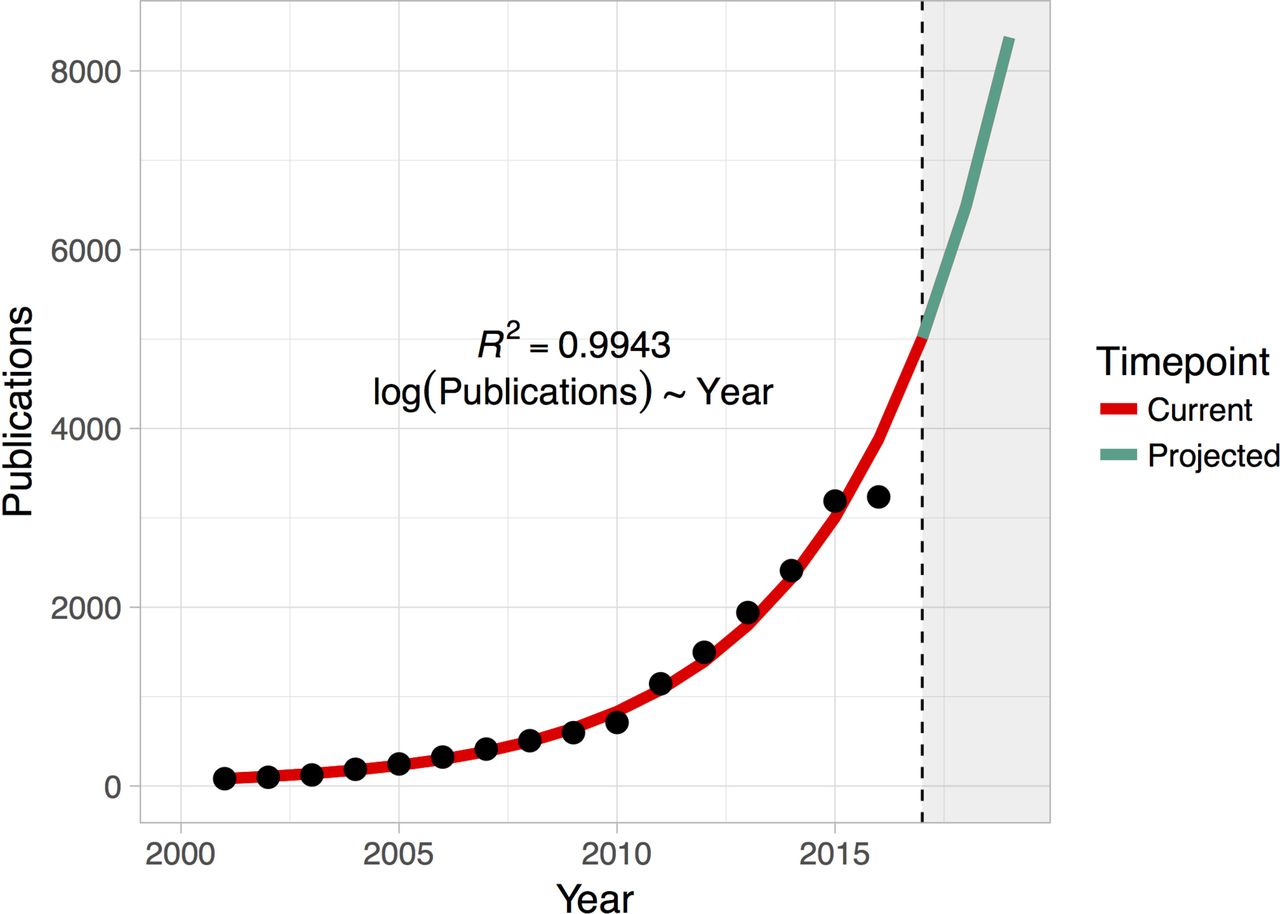
Cardiovascular medicine generates a plethora of biomedical, clinical and operational data as part of patient care delivery. Often these data are stored in diverse data repositories which are not readily utilisable for cardiovascular research due to challenges in automated abstraction and manual curation technical competency. Despite these challenges, the application of machine learning technologies in cardiovascular medicine is not new (figure 1). Scientists have long used computers and early techniques drawn from AI to analyse and interpret cardiovascular phenotyping data, for example, automated analysis of ECGs and imaging systems.3 However, renewed interest in AI is emerging due to the availability of a new generation of modern, scalable computing systems and algorithms capable of processing petabytes of data in real time. Furthermore, the high dimensionality of data increases analytical challenges and also simultaneously offers rich opportunities for improved discovery.4 A few specific types of cardiovascular data sets with immediate needs for exploration with machine learning approaches are discussed in detail below.

Projecting the growth of publications in PubMed with ‘cardiology’ and ‘machine learning’. Data compiled using Medline (PubMed) trend (http://dan.corlan.net/medline-trend.html). Exponentiated regression of log number of publications on year is used to predict the future trend.
Imaging and high-density phenotyping data
Cardiac imaging modalities like echocardiography, CT, MRI, single-photon emission CT, near-infrared spectroscopy, intravascular ultrasound and optical coherence tomography allow for visual assessment of structural changes. Since these structural changes are related to underlying disease aetiology and pathophysiological mechanisms, imaging is obviously widely used in cardiovascular medicine.5 Imaging data sets are complex and stored in a variety of formats (JPEG, MPEG, DICOM, and so on) and are of varying dimension and scale (two dimensional, three dimensional, four dimensional, and so on), thereby representing the leading edge of cardiovascular big data. For example, in a recent study around 20% of Medicare patients underwent echocardiography, accounting for approximately 7.07 million echocardiography examinations. Given that a single echocardiography examination generates 2 GB data, this means about 14 petabytes of echocardiography results are collected annually. Traditional statistical methods cannot efficiently handle and learn from such elaborate data sets to develop diagnostic and predictive models for assisting clinical decision-making. Machine learning, on the other hand, could play an important role in automating cardiovascular imaging workflows through faster reading, interpretation and diagnosis.6–9
High-throughput molecular profiling data
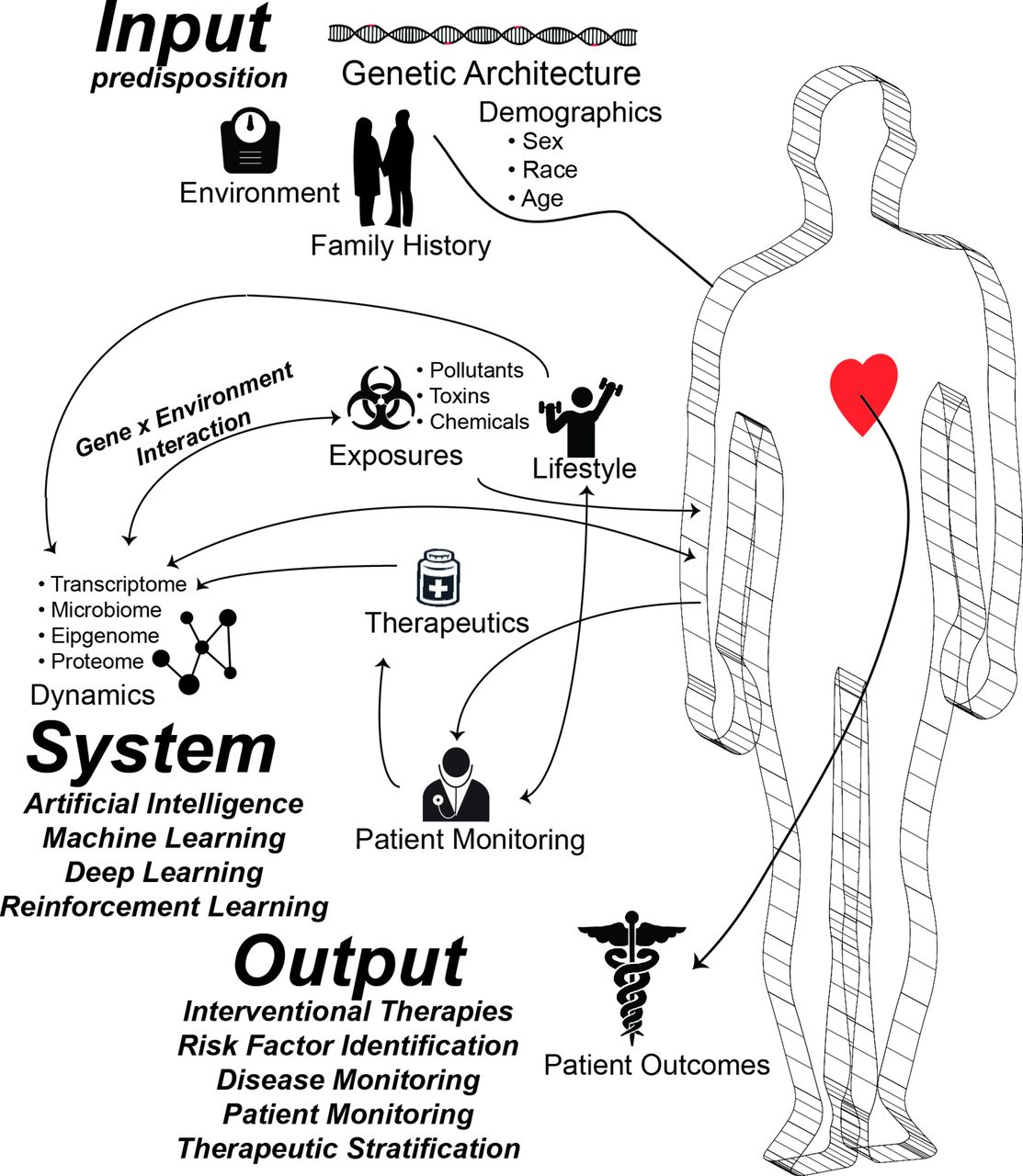
Different omics technologies may be applied to perform deep profiling of particular molecular entities (eg, genes -> genomics, RNAs -> transcriptomics, proteins -> proteomics). The genetic basis of cardiovascular disease (CVD) is a long-standing and fruitful theme in research and discovery. Due to the influx of low-cost, affordable genomic testing technologies, genomics in particular is emerging in cardiology. For example, polygenic risk scores are currently available that can predict and provide 2, 5 or 10-year forecasts of cardiovascular events like myocardial infarction, heart failure and stroke. In addition to the discovery of at-risk patients, genomic results can also help customise therapy selection (eg, warfarin dosing). Since 2007 and 2010, several large genome-wide association studies and phenome-wide association studies, respectively, have demonstrated that CVD pathophysiology results from the complex interaction of many genes, non-coding regions and regulatory proteins.10–12 Typically, a patient at risk is assessed for a potential cardiovascular event incidence (eg, heart attack, stroke, heart failure, and so on) using risk scores. Contrast these scores to more conventional scoring methods such as the Framingham Risk Score (FRS), a widely used risk score for predicting 10-year coronary heart disease risk based on age, gender and smoking status: notably, the FRS lacks any genomic component. However growing evidence from multiple studies suggests that incorporating genetic components and computing personalised genomic risk scores could play an important role in CVD risk estimation.13 In addition to genomics, emerging molecular profiling technology including transcriptomics, proteomics, epigenomics, metabolomics and compiling longitudinal microbiome data could provide new insights into the pathophysiology of CVDs (see table 1 and figure 2). In the future, such pan-omics data sets could be generated from patient samples and become a routine part of cardiovascular care. While high-throughput technologies provide insight into a large number of genes, proteins and metabolites pertinent to CVD, the integration and interpretation of these data often requires a combination of statistical and machine learning approaches. For example, using high-throughput differential gene expression analyses from microarrays or RNA sequencing using statistical methods provides a list of genes that are altered in the patients but not controls. This may provide insight into disease processes, but it is unlikely to be directly clinically applicable. Using a machine learning framework, a signature-based predictive model could be built and used to develop a new biomarker-based diagnostic test. Molecular profiling and downstream analyses using statistical and machine learning approaches can also aid in identifying new target molecules for drug discovery and drug repositioning.5 14 Emerging studies suggest that combining pan-omics technologies with imaging will be routine in the future to compile a stratified profile of patient population.5 For example, recently, Li et al demonstrated that layering genomic data on EHR-based phenomics can be used to find and characterise patient subtypes (in this case, for type 2 diabetes mellitus).15

An infographic depicting various elements amenable to machine learning in cardiovascular medicine.
High-dimensional and high-throughput molecular profiling experiments that require statistical and machine learning approaches for biological and clinical analyses and inferences
Data from clinical trials, population studies and disease registries
Current guidelines developed by various cardiovascular societies are implicitly based on an ‘average patient’.16 However, the complexity of human pathophysiology often cannot be adequately modelled by assuming patients conform to the same general rubric, and consequently, the guidelines may not be applicable for some patients. Machine learning tools can help develop standardised predictive models that could aid cardiologist with patient-specific guidelines. Such approaches can be considered a cognitive extension that augments rather than replaces physicians with AI for making patient-specific decisions. Importantly, accelerated and automated clinical decision-making would help providers to reclaim time and improve patient–provider interactions.
Need for machine learning in cardiovascular medicine
A primary difference between statistical methods and machine learning methods is that the former primarily help to understand relationships between a limited and a number of variables, but the latter contribute to identify and engineer features from the data and perform prediction. Machine learning methods thus complement and extend existing statistical methods—providing tools and algorithms to understand patterns from large, complex and heterogeneous data. Although classical statistical methods are capable of both discovery and prediction, machine learning methods are suitable and generalisable across a variety of data types and offer analyses and interpretation across complex variables.17 Additionally, machine learning techniques typically rely on fewer assumptions and provide superior and more robust predictions. Several major types of machine learning algorithms are described below:
Supervised learning
Supervised learning is a machine learning approach where the investigator uses a database of observations with labelled outcomes or classes. These data are generally used to develop a model to predict or classify future events, or to find which variables are most relevant to the outcome. Examples of supervised learning algorithms include ordinary least squares regression,18 logistic regression,19 least absolute shrinkage and selection operator (LASSO) regression,20 ridge regression,21 elastic net regression,21 linear discriminant analysis,22 Naïve Bayes classifiers,9 support vector machines,23 Bayesian networks,24 a variety of decision trees25 especially Random Forests26 and AdaBoost or gradient boosting classifiers,27 artificial neural networks and ensemble methods.7 Some of the examples of supervised machine learning tasks include regression, classification, predictive modelling and survival analysis. Supervised machine learning can help circumvent classification problems in phenotypically difficult patients (figure 3). For example, we recently described the use of supervised learning for differentiating athlete’s heart and hypertrophic cardiomyopathy.7 In another similar example, we developed a cognitive machine learning-based classifier to distinguish between constrictive pericarditis and restrictive cardiomyopathy.8
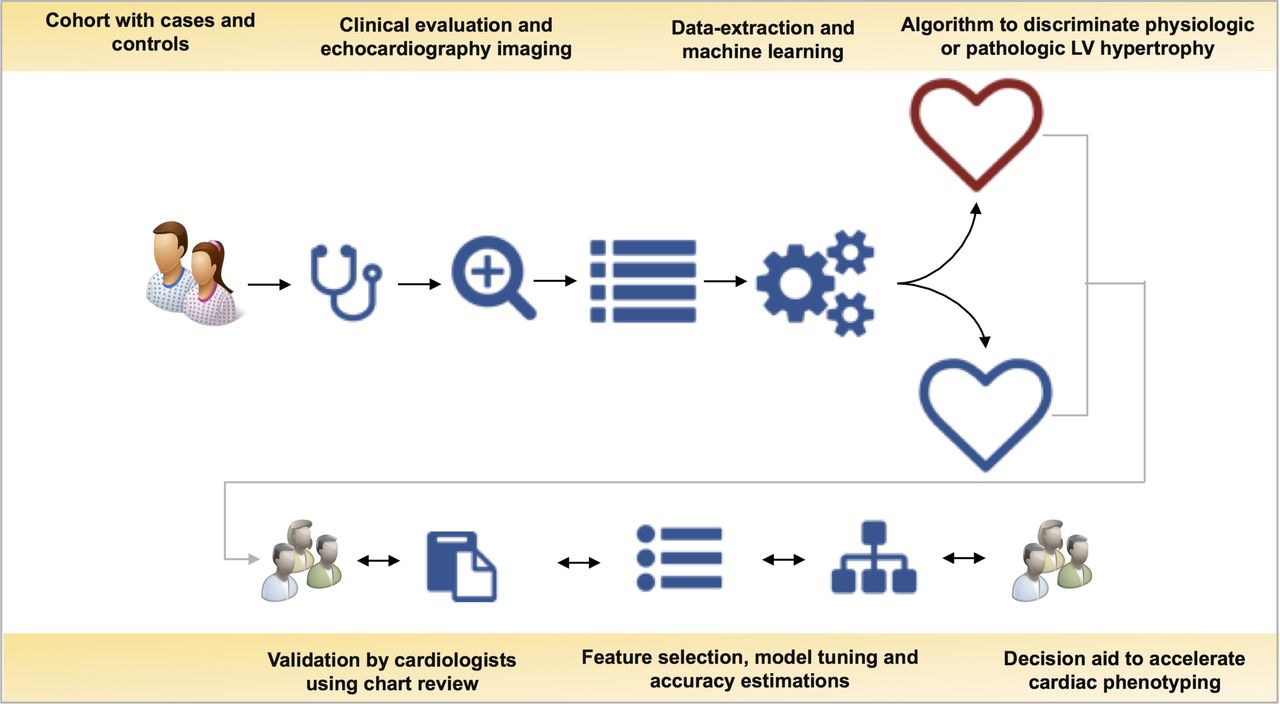
Cardiology informatics workflow used to develop a machine learning-based predictive model discriminates physiological function (athlete’s heart) from pathological (hypertrophic cardiomyopathy) function. LV, left ventricular.
Unsupervised machine learning
Unsupervised learning is a machine learning approach suitable for a data set with no prior label or annotation available. Instead, the goal is to learn the relationship between variables and uncover hidden structure in a data set. Examples of unsupervised learning include clustering methods (hierarchical or K means),28 principal component analysis, information maximising component analysis,29 self-organising maps,30 topological data analysis and deep learning. Specifically, deep learning is an emerging subdiscipline of machine learning that leverages an artificial neural network with many hidden layers of neurons. Deep learning algorithms can take a large number of features and derive neural network-based ‘representations’ that are capable of fast learning across a large number of samples.31 Deep learning algorithms are particularly well suited for computer vision. This enables computers to perform reasoning and interpretation of imaging, often using convolutional neural network-based representation.32 Currently, deep learning architectures are being applied to a variety of imaging-based calssifications.33–35 Developing deep learning models is computationally expensive, and this field is rapidly developing due to the increasing availability of high-performance computing infrastructure via cloud computing and graphical processing unit-based model building.31
Reinforcement learning
Reinforcement learning is another emerging subdiscipline of machine learning based on behavioural psychology. In classical machine learning, a model is trained and tested. Future predictions are based on this static model. Variants of this approach exist such as real-time machine learning. However, reinforcement learning uses an alternate approach where a software agent acts in a prespecified environment to maximise a reward. The agent thus discovers the appropriate behaviour using some ‘reward’ criteria to handle the decision-making function (policy). Currently, reinforcement learning is being used for medical image analytics,36 disease screening37 and personalised prescription selection.38 One particularly exciting example of reinforcement learning was then this method was used to select the optimal sequence of medications in non-small cell lung cancer.39 Because many problems in clinical medicine can be formatted to fit the format of a reinforcement learning problem, we envision that this method will be used, for example, to select personalised blood pressure drugs and dosages, intelligently segment medical imaging data, or to interview patients and extract relevant diagnostic information.
Design and evaluation of a machine learning-based classifier
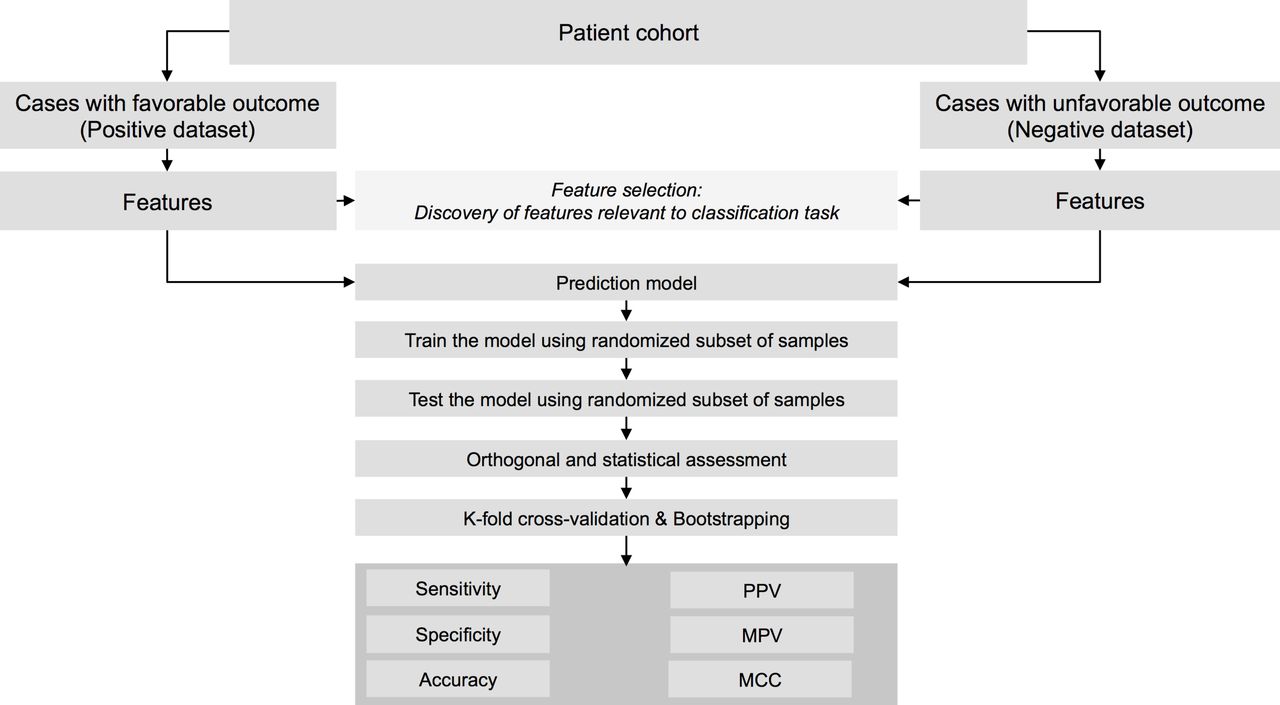
Figure 3 provides a generic outline of the various steps involved in the process of building predictive models. Supervised machine learning projects begin with formulating a predictive task to solve. Data can be aggregated prospectively with clinical trials or retrospectively from EHRs, clinical registries and other databases. After finalising the source databases, the data have to be checked, filtered and transformed depending on the data types and nature of the prediction task. Similar to a clinical trial, inclusion and exclusion criteria can be recommended and samples can be filtered out to ensure appropriateness, reproducibility and optimal performance. Typically, data sets are split into separate training and testing data sets. A predictive model is constructed using training data sets, and its performance is then evaluated on the held-out test data. Related but more sophisticated techniques for evaluating test/training splits such as K-fold or leave-one-out cross-validation can be used. Specific supervised learning performance statistics like Cohen’s kappa statistics, Matthew’s correlation coefficient, or F1 score augment traditional statistics like true positive rate, false positive rate, positive prediction value, negative prediction value, and so on (figure 3). In binary classification problems, overall model classification performance is often evaluated by computing the area under the receiver operating characteristic curve. Further refinement of a model can be achieved using the technique of feature selection. Feature selection consists of identifying the subset of predictor variables most relevant to a prediction task and removing the remaining features from the model. This helps to avoid overfitting a particular model to the training data set.
Delivering machine learning algorithms at the point of care
Predeveloped machine learning models can be stored in a computer to automatically perform precision phenotyping or patient acuity monitoring. The machine learning module may exist as standalone software; incorporated into a software suite for imaging, echo or other cardiovascular imaging modalities; as a cloud computing service provided by service providers such as Amazon Web Services, Microsoft Azure, Google Cloud Platform, or in a virtual private server-based system. Machine learning-based predictive models may also be embedded in EHRs or mobile device applications.
Challenges and opportunities
Need for orthogonal evidence from AI in cardiovascular medicine
Designing predictive and prescriptive models in cardiovascular medicine could help enable risk stratification and thus have significant implications in quality of healthcare delivery and impact on patient outcomes.40 However, machine learning algorithms are not a panacea and also have limitations. One especially important challenge is the interplay between overfitting and underfitting the data sets. Hence, assessing bias-variance trade-off is a key step for predictive model validation. In short, the success of a machine learning project depends on the number of observations, number of features, selection and parameterisation of features and algorithm chosen for the model. Most importantly, an optimal predictive model can only be as good as the signal within the input data sets. This limitation can be addressed by performing orthogonal validation with independent data or different data modality to further validate the machine learning-based feature selection and predictive analytics.
Generalisability of machine learning models
In a recent, methodologically sound study, Frizzell et al showed that machine learning approaches performed poorly compared with traditional statistical methods in the context of congestive heart failure readmission prediction.41 As the authors themselves conclude, results of their large-scale machine learning attempt to predict readmissions are largely not concordant with both earlier and emerging findings.9 42 Here, we would like to highlight the conceptual limitations of readmission prediction and challenges with modelling approaches presented. First, there is a philosophical difference between predictive logistic regression models and machine learning-based modelling strategies. All modelling strategies begin with assumptions, and structural limitations and successful modellers must remain cognisant of these. Clinical context, local factors (including physician preferences, federal, regional and local care standards), selection of medications and other clinical decisions influence the final design of the model. Heart failure is a complex, heterogeneous disease. Readmission, layered on top of this, adds an enormous amount of complexity due to biological, clinical, socioeconomic and psychological interactions. One solution to avoid the impact of such bias is the generalisation of prediction task and building of different predictive models for various regions, cities or even individual hospitals. We took such an approach to model readmission at our hospital, obtaining a significantly higher C-statistic (0.78) than those shown by Frizzell et al (AUCs in the range of 0.6–0.7). There is no a priori reason to expect that a model built with data from, for example, a hospital in New York City should be able to predict readmission in Mobile, Alabama. Bias due to variation in hospital-to-hospital care pathways is not accounted in the model by Frizzell et al; we assume these rates would be different across various hospitals in the cohort as the authors also did not perform a feature selection or accuracy assessment of a reduced representation model.43 It is reasonable to assume that the factors driving readmission in the different regions are different.43 In general, missing information will be a challenge when trying to draw clinical inferences from a data set. However, for several reasons, machine learning is often superior to traditional statistical methods in the context of missing data. First, machine learning methods tend to make fewer assumptions about the underlying data, which means that missing data that might challenge the assumptions of statistical models are less of an issue. Such approaches are being particularly helpful in ‘messy’ problems such as EHR-based inference. Second, modelling missing data using imputation technique is the most common method to deal with missing data. Empirical evidence shows that machine learning methods can be used to define, interpret and handle missing data as part of the predictive modelling in biomedicine than traditional statistical methods.
Causality versus association in machine learning
One notable feature of machine learning algorithms is that highly predictive variables are not necessarily causative for the outcome of interest. Hence, mere automated inference using machine learning would not be an ideal application in the setting of cardiovascular medicine; instead, leveraging interpretable models and features may help in democratising machine learning in cardiovascular medicine. Consider the example of a drug which correlates with increased mortality—it may instead be the case that the drug is merely a marker for an underlying disease, which causes mortality, and not the causative agent itself. A classic example that highlights the causality versus association in the setting of cardiology is the association of high-density lipoprotein (HDL) cholesterol—higher levels—with low CVD risk, but drugs that increase HDL (such as the trapibs) do not appear to markedly reduce cardiovascular risk. In this context, HDL could be an indirect or surrogate molecular marker at least in some of the disease subtypes, which is associated with coronary artery disease, but it does not participate in causing or alleviating it. To model the causality versus association problem, some solutions for causal inference have been developed such as Mendelian randomisation (MR) or statistical analysis based on directed acyclic graphs. MR is an emerging technique, which relies on the fact that genetic material is randomly inherited. A particular risk allele (eg, a single-nucleotide polymorphism (SNP) that changes low-density lipoprotein (LDL) cholesterol levels) can act as an instrumental variable for the exposure studies. As the prior knowledge suggests the SNP is causally affecting LDL levels, and the SNP is randomly inherited, if LDL levels are associated with the outcome we can assume a causal relationship. MR has been used in a number of cardiovascular studies to causally implicate factors like alcohol intake44 and LDL cholesterol.45 MR has recently been used to demonstrate that a biomarker associated with CVD (cystatin C) was not causally related.46 Teasing such complex causal and association effects is crucial to developing personalised therapies in cardiology. New methods are now being designed to integrate MR with machine learning for systematic and automated causal inference using large-scale population and phenomic data sets.47
Standardisation of machine learning using a minimum information model in the setting of biomedicine
Summarising evidence from multiple studies and meta-analyses are vital for developing guidelines and policy implementations in public health and medicine. However, to achieve such concordance using machine learning, a new policy on the dissemination and reporting of machine learning models in medicine is required. Publications should report minimum sets of data elements: for example, all model parameters should be provided, and the manuscript should also communicate variables using a standard ontology (see table 2). Any data transformations applied to the data, sampling methods and random number generator seeds should be disclosed. Further, all data, version numbers of software and associated code should be released in a public domain software archive system to enable replication. Journals and researchers could adopt such a minimum information model for machine learning and mandate use in the cardiovascular medicine community. Clinician investigators and data scientists need to come together for defining data sharing and usage policy. Compiling data for various disease phenotypes and therapeutic stratifications amenable to machine learning from healthcare providers and health systems is crucial to improve the generalisability and predictive provenance of clinical algorithms for learning and prediction. Such efforts would help reduce ambiguity and promote the adoption of machine learning as a standard mode of data interpretation in the cardiology community.
Open access biomedical and healthcare ontologies and big data resources in cardiovascular medicine for developing machine learning resources
Engaging cardiovascular medicine stakeholders in machine learning
Patients regularly pose questions that may be difficult to answer without data-driven analytics. For example, ‘Are there many patients similar to me treated here?’, ‘What was the direct outcome of my treatment?’, ‘Are there any alternative treatment options?’, or ‘Are there other medications to reduce my symptom burden?’. Providers are keen to improve their overall quality of patient care. Payers are interested in providing optimal care to a patient with minimal investment, thus ensuring maximum return on investment. The pharmaceutical industry is engaged in development and delivery of therapies that suit a patient. As healthcare is driven by these four related, yet diverse stakeholders, engaging them to need an all-encompassing strategy satisfies the multitude of requirements. Thus, tools to identify population-level risk and infer the individual risk of a patient are key. We envisage that machine learning-based, hyperlocal analytics would allow a primary care physician or cardiologist to answer these questions with clarity. Collectively, engaging patients, providers, payers and pharma to leverage modern analytical approaches as part of routine clinical care may improve outcomes and overall survival. To encourage the use of machine learning-based methods, medical students should be trained in the application of both statistical and machine learning in medicine and healthcare (table 3). The physician of the future must be both a clinician and a data scientist. Indeed, the ability to apply advanced data science concepts to clinical care may ultimately prove to be a decisive differentiator between physicians and mid-level providers. Initiating machine learning contests and challenging students, residents and trainees, as part of major cardiovascular conferences, would further improve the adoption of machine learning in cardiovascular medicine.48
Differentiating data-driven, machine learning approaches compared with statistical approaches
Limitations of machine learning in cardiovascular medicine
Statistical methods have been applied to biomedical problems for decades, from old and ubiquitous inventions such as survival analysis with Cox’s proportional hazard regression, to the design of LASSO regression for the analysis of genotyping data. In general, methods like these aim to identify, quantify and interpret the relationship between variables. In abstract, this is necessarily the same goal as most machine learning and AI methods when applied to cardiology. In our view, there is not a sharp distinction between statistics and machine learning; but instead, the respective sets of methods exist on a continuum defined primarily by motivations for their creation and application. LASSO, in particular, is often interpreted as a machine learning method, although it is an extension of regression techniques. For example, parametric statistical methods assume distributions for each variable and then attempt to model the probability of a given set of observations. In both supervised and unsupervised machine learning, we are often interested in solving the same class of problem. Thus, classical statistics methods like logistic regression are essentially forms of ‘machine learning’. However, machine learning has emerged because in many cases more classical methods are either inefficient or less accurate in real-world situations. As we discussed in the previous example, logistic regression relies on assumptions that are often unrealistic, requiring variables to have log odds linearly related to an outcome, continuous decision boundaries in classification problems, independence of observations and errors, and so on. In contrast, many machine learning methods require far fewer assumptions of the given data: methods like Random Forests have virtually no statistical assumptions of the data; we only aim to apply an algorithm and ‘see how it works.’ This approach is particularly useful because, in reality, no complex problem is linear—Random Forests and more sophisticated AI methods like deep learning can learn highly complex relationships from the data, which often results in far better performance in prediction, clustering and other tasks.
Similar to statistical and mathematical methods, careful design and evaluation of machine learning models is an important aspect. Various factors including data quality, data integration strategy, choice of machine learning algorithm, validation methods, orthogonal evidence, the clinical and biological relevance of the machine learning model and comparative effectiveness to the standard of care affect a machine learning model in the setting of cardiovascular medicine.2 Choice of methods used for data and integrating data from various database systems and normalising to a single data model is critical. Assigning appropriate case–control labels and validating manual or automated abstraction algorithms are also crucial. Without extensive evaluation, models are often overfit to training data, and hence following a structured machine learning workflow (see figure 4) defined and proposed by the cardiovascular medicine community is a need of the hour. In this context, we want to emphasise the relevance of Dr Box’s quote on statistical models, ‘All models are wrong, but some are useful.’49
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Architecture of a machine learning model to predict a binary outcome. MCC, Mathew’s Correlation Coefficient; NPV, Negative Predictive Value; PPV, Positive Predictive Value.
Conclusions
In this review article, we reviewed the basics of machine learning algorithms and what potential data sources exist in medicine; examined the need for AI in medicine; and evaluated the potential limitations and challenges of implementing AI in medicine. With the increasing availability of big data sourced from different avenues of biomedicine and healthcare delivery and the progression towards precision medicine approaches, the application of AI for analyses and interpretation of medical data will continue to grow. CVDs represent groups of diseases that can benefit greatly from pre-emptive prediction, prevention and proactive management, and thus AI methodologies. Various types of AI algorithms will be essential for understanding the nuanced individual risk factors, behavioural drivers and therapeutic pathways predictive of disease outcomes in specific patient cohorts and also for instituting early therapeutic interventions. The application of machine learning algorithms in prospective clinical trials would allow comparison with current standard of care practices with a goal of implementing precision diagnostics, risk stratification and personalised therapeutics. Various machine learning methods like supervised learning, cognitive learning and unsupervised learning methods including deep learning could uncover hidden structure in big data in cardiology and can help subtype chronic complex diseases common in cardiovascular medicine; such insights may also lead to novel therapeutic discoveries and help improve delivery of personalised cardiovascular care. While there exist compelling debates in medicine about whether AI will replace doctors in the near future, we believe it will instead primarily augment and extend the current practice of healthcare delivery, thus improving the lives of patients, providers and society at large.
References
Footnotes
Contributors PPS and JTD planned the outline of the article. KS, KWJ and BSG conducted the empirical analyses and literature survey, and compiled the figures. All authors contributed to the manuscript writing and editing.
Funding KS, KWJ, BSG and JTD acknowledge support from the National Institutes of Health: National Institute of Diabetes and Digestive and Kidney Diseases (NIDDK, grant number R01-DK098242-03); National Cancer Institute (NCI, grant number U54-CA189201-02); Illuminating the Druggable Genome (IDG); Knowledge Management Center sponsored by NIH Common Fund; National Center for Advancing Translational Sciences (NCATS, grant number UL1TR000067); and Clinical and Translational Science Awards (CTSA) grant.
Competing interests PPS is a consultant for TeleHealthRobotics, HeartSciences and Hitachi-Aloka. JTD has received consulting fees or honoraria from Janssen Pharmaceuticals, GlaxoSmithKline, AstraZeneca and Hoffman-La Roche. JTD is a scientific advisor to LAM Therapeutics and holds equity in NuMedii, Ayasdi and Ontomics. KS has received consulting fees or honoraria from Philips Healthcare, Google, LEK Consulting and Parthenon-EY. All other authors declare no competing interests.
Provenance and peer review Commissioned; externally peer reviewed.